
查询
HiSql 提供一个可以适合多种数据库的中间查询语法,不需要关注各个数据库的语法特性,通过HiSql写语句可以在常用的不同类型数据库中执行,且语法与Sql语境类似一看就懂一学就会
提示
HiSql 查询方式提供两种查询方式
- 链式写法
- HiSql 语句 (非原生数据库的语句,但类似于SQL的语法可以跨库执行) 一套中间SQL语句 详请见
HiSql语法文档
HiSql主要的方向是低代码平台(低代码平台的特点是用户可以建表,如果建一张表要对应一个实体是行不通的) 所以暂时不支持Lambda表达式的写法,写也是HiSql与其它ORM框架的区别之一
单表查询
HiSql生成的语句
通过ToSql可以查看当前操作生成的底层Sql语句 注:不同的数据库生成的语句会有差别
提示
HiSql底层对于SQL语句进行了AST语法,语义解析能智能识别语法错误
//返回当前连接数据库类型的SQL查询语句
string sql1=sqlClient.Query("Hi_TabModel").Field("*").ToSql();
2
//返回当前连接数据库类型的SQL查询语句
// 注意这不是原生的sql语句 是HiSql定义的一套跨数据库的中间SQL语句 详请见[HiSql语法] 文档
string sql2=sqlClient.HiSql("select * from Hi_TabModel").ToSql();
2
3
在执行ToSql() HiSql会检测查询的表及字段的合法性,只要检测通过了才会编译成对应数据库的Sql查询语句
生成的SQL语句如下(SqlServer为例)
select [Hi_TabModel].[TabName],[Hi_TabModel].[TabReName],[Hi_TabModel].[TabDescript],[Hi_TabModel].[TabStoreType],[Hi_TabModel].[TabType],[Hi_TabModel].[TabCacheType],[Hi_TabModel].[TabStatus],[Hi_TabModel].[IsSys],[Hi_TabModel].[IsEdit],[Hi_TabModel].[IsLog],[Hi_TabModel].[LogTable],[Hi_TabModel].[LogExprireDay],[Hi_TabModel].[CreateTime],[Hi_TabModel].[CreateName],[Hi_TabModel].[ModiTime],[Hi_TabModel].[ModiName] from [Hi_TabModel] as [Hi_TabModel]
2
3
可能有人会问为什么*号会带出来所有的字段是不是生成的语句有问题?
提示
当字段使用*号时会查询表中所有的字段,如果字段的顺序要调整请修改系统表Hi_FieldModel中的SortNum的值,值越小排在越前面(当物理表中的字段顺序不是想要的但又不想修改物理表可以通过该方式调整顺序) 为了可以自定义排序所以会带出字段,不过没有关系这里不影响性能
单表查询结果
hisql查询的查询语法与sql类似 提供了四种查询结果的返回类型
ToTable()返回一个DataTable表结果ToJson()返回一个Json结果集ToList<T>返回一个实体类集合 T 的类的属性必须与返回的结果集有字段相匹配ToDynamic()返回一个动态类集 HiSql.TDynamic 可以查看文档ToEObjectAsync()返回ExpandObject类集 (1.0.2.9及以上版本才支持)
//查询表Hi_TabModel的所有字段 并返回一个 DataTable的结果集
DataTable dt1= sqlClient.Query("Hi_TabModel").Field("*").ToTable();
2
//查询表Hi_TabModel的所有字段 并返回一个 DataTable的结果集
// 注意这不是原生的sql语句 是HiSql定义的一套跨数据库的中间SQL语句 详请见[HiSql语法] 文档
DataTable dt2= sqlClient.HiSql("select * from Hi_TabModel").ToTable();
2
3
4
查询指定字段
Field()方法支持多参数(params string[] )的字段 注意不要带数据库底层的符号如sqlserver [字段名] ,hisql在生成sql时将会自动处理
//仅查询表Hi_TabModel的部分字段 并返回一个 DataTable的结果集
DataTable dt= sqlClient.Query("Hi_TabModel").Field("TabName","TabReName").ToTable();
2
3
4
//仅查询表Hi_TabModel的部分字段 并返回一个 DataTable的结果集
// 注意这不是原生的sql语句 是HiSql定义的一套跨数据库的中间SQL语句 详请见[HiSql语法] 文档
DataTable dt= sqlClient.HiSql("select TabName,TabReName from Hi_TabModel").ToTable();
2
3
生成的SQL语句如下(SqlServer为例)
select [Hi_TabModel].[TabName],[Hi_TabModel].[TabReName] from [Hi_TabModel] as [Hi_TabModel]
单表分页查询
Skip表示取的页码数Take表示每页获取数量Sort可以支持多种方式如Sort("createtime desc")注意这个适用于Hisql支持的所有库(不要用底层库的语法不然Hisql检测时会抛出异常)Sort("createtime desc","TabName asc")多个排序条件时可以这样写Sort(new SortBy { { "createtime",SortType.DESC} })也支持这种写法Sort(new SortBy { { "createtime",SortType.DESC} , { "TabName", SortType.ASC } })多个参数写法
//方式1
DataTable dt1= sqlClient.Query("Hi_TabModel").Field("*")
.Sort("createtime desc"). Skip(1).Take(100).ToTable();
//方式2
DataTable dt2 = sqlClient.Query("Hi_TabModel").Field("*")
.Sort(new SortBy { { "createtime",SortType.DESC} }).Skip(1).Take(100).ToTable();
//如果需要返回当前查询条件的记录总数
int _total=0;
DataTable dt3 = sqlClient.Query("Hi_TabModel").Field("*")
.Sort(new SortBy { { "createtime",SortType.DESC} }).Skip(1).Take(100).ToTable(ref _total);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
DataTable dt4= sqlClient.HiSql("select * from Hi_TabModel").Skip(1).Take(100).ToTable();
//如果需要返回当前查询条件的记录总数
int _total=0;
DataTable dt5 = sqlClient.HiSql("select * from Hi_TabModel").Skip(1).Take(100).ToTable(ref _total);
2
3
4
5
6
提示
在HiSql底层会根据页码生在不同的分页方式以追求性能极致
Where条件查询
HiSql提供了多种查询语句的写法总有一款适合你
HiSql查询条件的特点是可以动态拼接(非生成数据库SQL),这是其它ORM框架完全不具备的用Lambda表达式的方式如果要拼动态条件试过的人都知道多痛苦,如果用原生SQL是无法跨库支持的且完全性不可控(sql注入),HiSql在底层编译器解析成不同的数据库语句。有兴趣的可以试一下ToSql()方法查看一下编译出来的SQL
可能有些人会问?用表达式这种强类型的不好吗? 当然好还是那句话如果你的项目不涉及到动态的或与低代码相关的建议你用传统的ORM工具,如果你的项目想做成高度配置型的HiSql将是不错的选择
//单值
DataTable dt1 = sqlClient.Query("Hi_FieldModel").Field("*").Where(new Filter { { "TabName", OperType.EQ, "HTest01" } }).ToTable();
//多值查询 或查询
DataTable dt2 = sqlClient.Query("Hi_FieldModel").Field("*").Where(new Filter {
{ "TabName", OperType.EQ, "HTest01" },
{ LogiType.OR},
{ "FieldName", OperType.EQ, "UName" }
}).ToTable();
DataTable dt3 = sqlClient.Query("Hi_FieldModel").Field("*").Where(new Filter { { "TabName", OperType.EQ, "HTest01" } }).ToTable();
2
3
4
5
6
7
8
9
//注意这不是原生的sql语句 是HiSql定义的一套跨数据库的中间SQL语句 详请见[HiSql语法] 文档
//hisql语法
DataTable dt4 = sqlClient.HiSql("select * from Hi_FieldModel as a where a.TabName='HTest01'").ToTable();
DataTable dt5 = sqlClient.HiSql("select * from Hi_FieldModel where TabName='HTest01'").ToTable();
DataTable dt6 = sqlClient.HiSql("select * from Hi_FieldModel where (TabName='HTest01' or FieldName='UName')").ToTable();
2
3
4
5
DataTable dt7 = sqlClient.Query("Hi_FieldModel").Field("*").Where("TabName='HTest01'").ToTable();
DataTable dt8 = sqlClient.Query("Hi_FieldModel").Field("*").Where("(TabName='HTest01' or FieldName='UName')").ToTable();
2
子查询
上面介绍的查询方式大家可能都看得出来查询是比较简单的,如果涉及到子查询怎么样写呢?下来就来演示一下
DataTable dt1= sqlClient.Query("Hi_FieldModel").Field("*").Where(new Filter { { "TabName", OperType.IN,
sqlClient.Query("Hi_TabModel").Field("TabName").Where(new Filter { {"TabName",OperType.IN,new List<string> { "HTest01", "Hi_TabModel" } } })
} }).ToTable();
2
3
//注意这不是原生的sql语句 是HiSql定义的一套跨数据库的中间SQL语句 详请见[HiSql语法] 文档
DataTable dt2 = sqlClient.HiSql("select * from Hi_FieldModel where TabName in (select TabName from Hi_TabModel where TabName in ('HTest01','Hi_TabModel'))").ToTable();
2
3
生成的SQL语句如下(SqlServer为例)
select [Hi_FieldModel].[TabName],[Hi_FieldModel].[FieldName],[Hi_FieldModel].[FieldDesc],[Hi_FieldModel].[IsIdentity],[Hi_FieldModel].[IsPrimary],[Hi_FieldModel].[IsBllKey],[Hi_FieldModel].[FieldType],[Hi_FieldModel].[SortNum],[Hi_FieldModel].[Regex],[Hi_FieldModel].[DBDefault],[Hi_FieldModel].[DefaultValue],[Hi_FieldModel].[FieldLen],[Hi_FieldModel].[FieldDec],[Hi_FieldModel].[SNO],[Hi_FieldModel].[SNO_NUM],[Hi_FieldModel].[IsSys],[Hi_FieldModel].[IsNull],[Hi_FieldModel].[IsRequire],[Hi_FieldModel].[IsIgnore],[Hi_FieldModel].[IsObsolete],[Hi_FieldModel].[IsShow],[Hi_FieldModel].[IsSearch],[Hi_FieldModel].[SrchMode],[Hi_FieldModel].[IsRefTab],[Hi_FieldModel].[RefTab],[Hi_FieldModel].[RefField],[Hi_FieldModel].[RefFields],[Hi_FieldModel].[RefFieldDesc],[Hi_FieldModel].[RefWhere],[Hi_FieldModel].[CreateTime],[Hi_FieldModel].[CreateName],[Hi_FieldModel].[ModiTime],[Hi_FieldModel].[ModiName] from [Hi_FieldModel] as [Hi_FieldModel]
where [Hi_FieldModel].[TabName] in (select [Hi_TabModel].[TabName] from [Hi_TabModel] as [Hi_TabModel]
where [Hi_TabModel].[TabName] in ('HTest01','Hi_TabModel')
)
2
3
4
5
虽然两种不同的写法,但是生成的语句是一模一样的,HiSql内置了HiSql语句编译器有兴趣的可以看一下源码,实现原理与其它ORM框架有着本质匹别解析性能比Lambda表达式方式要强
分类汇总查询
HiSql支持max,min,avg,sum,count 五种常用聚合函数
DataTable dt = sqlClient.Query("Hi_FieldModel").Field("FieldName", "count(FieldName) as CHARG_COUNT").Group(new GroupBy { { "FieldName"} }).ToTable();
DataTable dt2 = sqlClient.HiSql("select FieldName,count(FieldName) as CHARG_COUNT from Hi_FieldModel group by FieldName").ToTable();
2
生成的sql如下(以sqlserver为例)
select [Hi_FieldModel].[FieldName],count(*) as CHARG_COUNT from [Hi_FieldModel] as [Hi_FieldModel]
group by [Hi_FieldModel].[FieldName]
2
3
4
对分类汇总不跳号排名
相有多个值同时则并列排名
DataTable dt_dens= sqlClient.Query("Hi_FieldModel").Field("FieldName", "count(FieldName) as CHARG_COUNT")
.Group(new GroupBy { { "FieldName" } })
.WithRank(DbRank.DENSERANK, DbFunction.COUNT, "FieldName", "rowidx1", SortType.DESC).ToTable();
2
3
4
生成的sql如下 (sqlserver)
select [Hi_FieldModel].[FieldName],count(*) as CHARG_COUNT,
dense_rank() over( order by COUNT([FieldName]) DESC) as rowidx1
from [Hi_FieldModel] as [Hi_FieldModel]
group by [Hi_FieldModel].[FieldName]
2
3
4
5
查询结果如下
并列第一的都是第1名 但第二名这个号没有被占用,这种叫不跳号排名
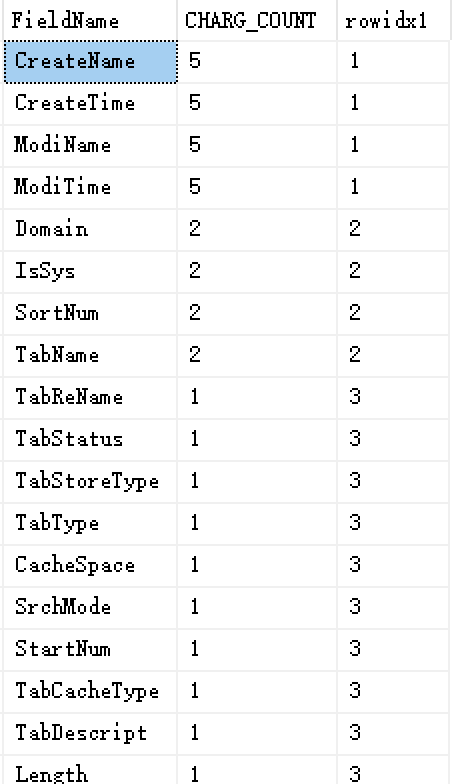
分类汇总跳号排名
DataTable dt_rank = sqlClient.Query("Hi_FieldModel").Field("FieldName", "count(FieldName) as CHARG_COUNT")
.Group(new GroupBy { { "FieldName" } })
.WithRank(DbRank.RANK, DbFunction.COUNT, "FieldName", "rowidx2", SortType.DESC).ToTable();
2
3
4
生成的sql如下(sqlserver)
select [Hi_FieldModel].[FieldName],count(*) as CHARG_COUNT,
rank() over( order by COUNT([FieldName]) DESC) as rowidx2
from [Hi_FieldModel] as [Hi_FieldModel]
group by [Hi_FieldModel].[FieldName]
2
3
4
5
查询结果如下 当有几个并列第一时则跳过这此号 称为跳号排名
分类汇总结果增加行号
var dt1 = sqlClient.Query(
sqlClient.Query("Hi_FieldModel").Field("*").WithLock(LockMode.ROWLOCK).Where(new Filter { { "TabName", OperType.IN,
sqlClient.Query("Hi_TabModel").Field("TabName").Where(new Filter { {"TabName",OperType.IN,new List<string> { "Hone_Test", "H_TEST" } } })
} }),
sqlClient.Query("Hi_FieldModel").WithLock(LockMode.ROWLOCK).Field("*").Where(new Filter { { "TabName", OperType.EQ, "DataDomain" } }),
sqlClient.Query("Hi_FieldModel").Field("*").Where(new Filter { { "TabName", OperType.EQ, "Hi_FieldModel" } })
)
.Field("TabName", "count(*) as CHARG_COUNT")
.WithRank(DbRank.DENSERANK, DbFunction.NONE, "TabName", "rowidx1", SortType.ASC)
//.WithRank(DbRank.ROWNUMBER, DbFunction.COUNT, "*", "rowidx2", SortType.ASC)
//以下实现组合排名
.WithRank(DbRank.ROWNUMBER, new Ranks { { DbFunction.COUNT, "*" }, { DbFunction.COUNT, "*", SortType.DESC } }, "rowidx2")
.WithRank(DbRank.RANK, DbFunction.COUNT, "*", "rowidx3", SortType.ASC)
.Group(new GroupBy { { "TabName" } }).ToTable();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
多表查询
join 查询
大家可以对比与其它框架的写法,HiSql的语法更贴近于数据库的SQL语句,学习成本更低,且其它ORM框架由于受泛型类的限制,对Join表的数量是有限制的。
DataTable dt1 = sqlClient.Query("Hi_FieldModel", "A").Field("A.FieldName as Fname")
.Join("Hi_TabModel").As("B").On(new JoinOn { { "A.TabName", "B.TabName" } })
.Where(new Filter { { "A.TabName",OperType.EQ, "HTest01" } })
.ToTable();
2
3
4
DataTable dt2 = sqlClient.HiSql("select A.FieldName as Fname from Hi_FieldModel as A inner join Hi_TabModel as B on A.TabName = B.TabName where A.TabName='HTest01'").ToTable();
2
生成的sql如下 (sqlserver)
select [A].[FieldName] as [Fname] from [Hi_FieldModel] as [A]
inner join [Hi_TabModel] as [B] on [A].[TabName]=[B].[TabName]
where [A].[TabName] = 'HTest01'
2
3
4
5